VideoRAG 这篇讲的是一个很现实的问题:视频越来越长,VLM 的上下文却不可能无限大。你不能把几小时的视频每一帧都塞进模型,于是就需要先检索,再让模型只看关键片段。
这篇文章把 VideoRAG 的思路拆成了图谱文本 grounding、视频多模态 embedding、LLM 过滤和最终回答生成。它有点像把 GraphRAG 和视频理解结合起来。

为什么普通 RAG 处理不了长视频
文本 RAG 的输入是文档,视频 RAG 的输入则复杂得多。视频里同时有画面、字幕、语音、场景变化、人物动作和跨时间事件。
如果只把 ASR 转录文本拿出来做 RAG,会丢掉很多视觉信息。比如“画面里车是什么颜色”“演示界面上点了哪个按钮”“某个图表出现在哪一段”,这些问题光看字幕不够。
如果直接让 VLM 看全部视频,又会遇到上下文和计算成本问题。VideoRAG 的做法是把长视频切成短 clip,提前建立混合索引,查询时只取相关片段。
双通道索引
VideoRAG 的索引阶段有两条线。
第一条是文本和图谱线。每个视频先被切成短片段,视觉内容由 VLM 生成 caption,音频由 ASR 转成 transcript。caption 和 transcript 合起来作为文本知识。
然后 LLM 从这些文本里抽取实体和关系,构建知识图谱。比如从“GPT-4 uses transformer architecture”里抽出 GPT-4、transformer architecture,以及“uses”关系。
第二条是多模态 embedding 线。每个视频片段会通过 CLIP 或 ImageBind 这类编码器生成视觉/多模态向量,方便后面按画面语义检索。
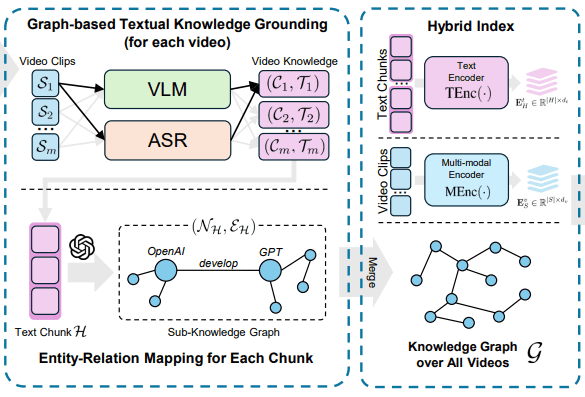
这两条线合起来,就是 VideoRAG 的 hybrid index:图谱 + 文本 embedding + 视频 clip embedding。
查询时怎么走
用户提问后,VideoRAG 先让 LLM 改写查询,把问题变成更适合检索的声明式表达。然后同时走图谱检索和 embedding 检索。
图谱检索负责找相关实体、关系和文本块。视觉检索负责把问题里的场景描述映射到相关视频片段。两个结果汇合后,再用一个轻量 LLM 做 judge,过滤掉看起来相关但实际答不上问题的片段。
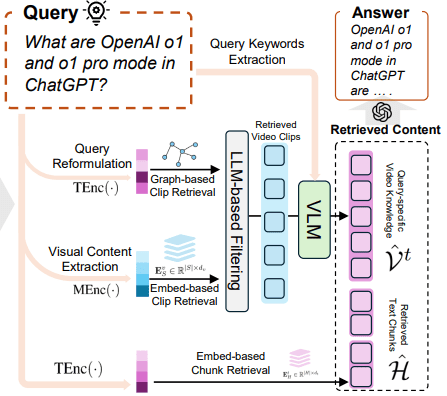
最后,被保留下来的 clip 会再次经过 VLM 生成更贴合问题的 caption,并和 ASR transcript 一起组成上下文,交给最终 LLM 生成回答。
Vimo 桌面实现
原文还介绍了官方实现 Vimo。它是 VideoRAG 的桌面应用形态,流程大致是:
git clone https://github.com/HKUDS/VideoRAG.git
cd Vimo-desktop
conda create --name vimo python=3.11
conda activate vimo
然后安装依赖,包括 PyTorch、moviepy、ImageBind、neo4j、hnswlib、nano-vectordb、openai、dashscope、flask 等。
后端启动:
cd python_backend
python videorag_api.py
前端启动:
pnpm install
pnpm dev
应用启动后,需要配置 OpenAI API key 和 Alibaba Dashscope API key。原文里用 gpt-4o-mini 做 LLM-as-a-judge,用 qwen-vl-max-latest 做 captioning。

适合什么场景
VideoRAG 比较适合长视频知识库,而不是短视频摘要。比如:
- 多小时课程检索
- 会议录像问答
- 产品演示视频知识库
- 纪录片内容问答
- 多段教程视频跨片段推理
它的优势是可以跨多个视频找证据,并把文本和视觉信息结合起来。缺点也明显:工程链路比较长,需要 ASR、VLM caption、图谱抽取、向量索引、LLM judge 和最终生成,成本不低。
我的理解
VideoRAG 的核心不是“让模型看更长视频”,而是“别让模型看没必要看的视频”。这和文档 RAG 的思想一致,只是视频场景需要多模态索引和视觉证据。
如果你正在做企业培训视频、产品教程库或会议录像检索,它的架构很值得参考。即使不完整复现,也可以借鉴其中的 clip 切分、ASR+caption 双文本、视觉 embedding 和 LLM 过滤机制。